
一、从概念模型出发,深入理解CiteSpace知识图谱分析的理论依据
CiteSpace是Citation Space的简称,可译为“引文空间”,这一命名深度浓缩了开创者陈超美教授本人的设计理念以及软件的核心功能——构建科学知识图谱以实现对引文的可视化分析。CiteSpace最初专门为进行文献的共引分析而设计,用以挖掘引文空间的知识基础与研究前沿,其理论依据和结构基础相较于在后续更新中拓展提供的对于其他科技文本知识单元(如关键词、术语、领域的共现,作者、机构、国家/地区的合作等)的分析功能也相对更加清晰和完备。结合实际使用过程中的感受,个人认为文献的共被引分析是CiteSpace核心功能,而不是关键词共现分析,这一观点在官方操作指南和配套书籍中同样也有体现,但一些网络社区文章或视频教程中可能对CiteSpace用法存在一定误导,需要使用者格外注意。在实际的数据分析中,使用者需要对CiteSpace背后的理论基础有所了解,尤其是对其方法论功能上的认识和理解,并根据自身的研究目的来选择合适的分析图谱类型,避免对可视化工具的滥用或误用情况。
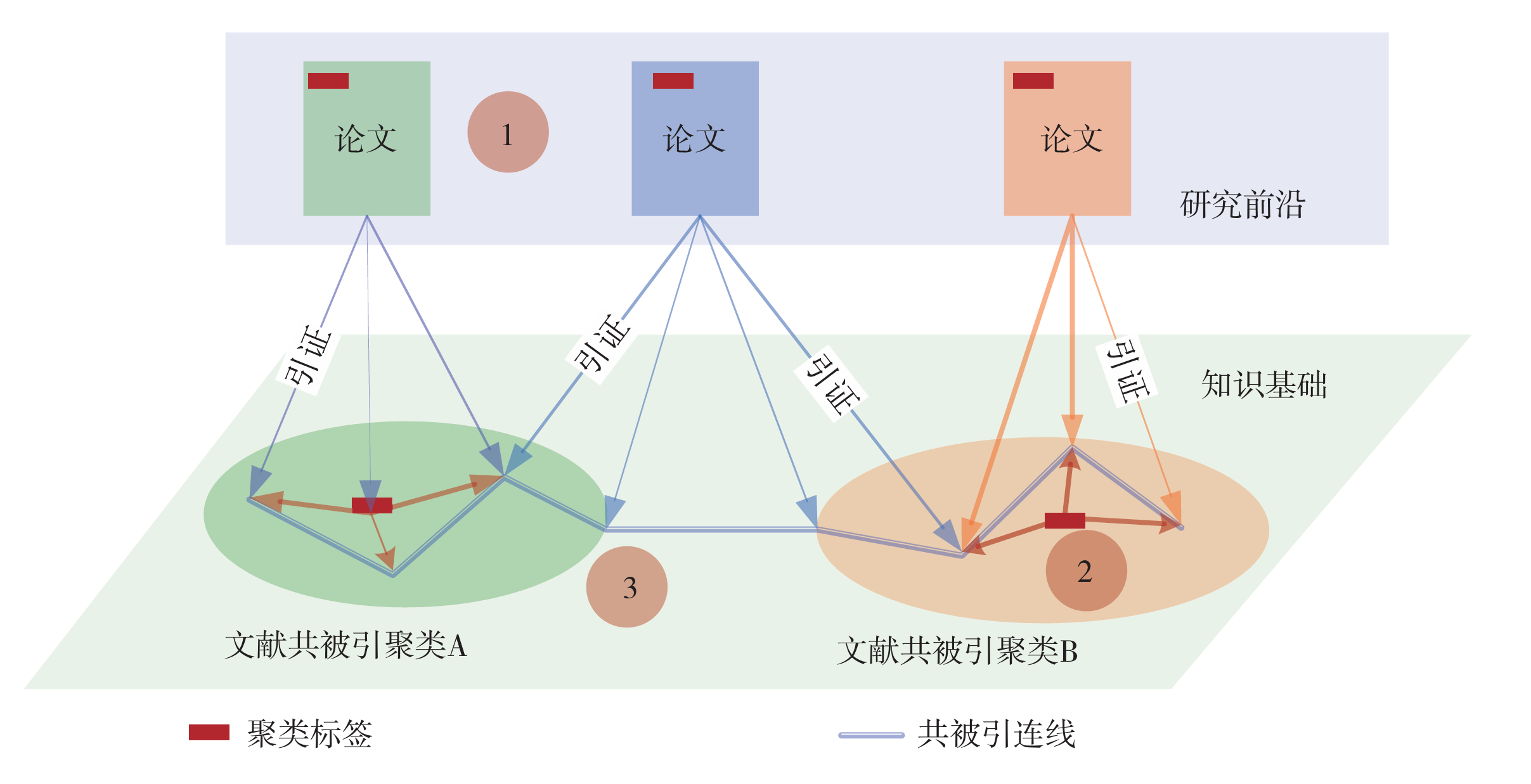
官方给出了CiteSpace的概念模型,如上图所示,知识基础是由共被引文献集合组成的,而研究前沿是由引用这些知识基础的施引文献集合组成的;CiteSpace对聚类标签的命名是通过从施引文献中提取的名词性术语确定的,这个命名可以认为是领域的研究前沿。
在CiteSpace中,研究前沿是正在兴起的理论趋势和新主题的涌现,共引网络则组成了知识基础。在分析时可以利用从题目、摘要等部分提取的突发性术语与共引网络的混合网络来进行分析(即共引文献和引用了这些文章术语的复合网络)。具体来说,一个研究领域可以被概念化成一个从研究前沿 Ψ(t) 到知识基础 Ω(t) 的时间映射 Φ(t),即 Φ(t): Ψ(t) → Ω(t)。CiteSpace实现的功能就是能够识别和显示 Φ(t) 随时间发展的新趋势和研究主题的突变。Ψ(t) 可以是一组在 t 时刻与新趋势和突变密切相关的术语,这些术语被称为前沿术语,Ω(t) 则是由出现前沿术语的文章引用的大量文章组成。
这里需要有所区分理解的是,研究热点可以认为是在某个领域中学者共同关注的一个或者多个话题,从“研究热点”的字面上理解,其有很强的时间特征。一个专业领域的研究热点保持的时间可能有长有短,CiteSpace中提供了对研究主题的词频、主题时间趋势、主题的突发性、主题的网络属性等分析的功能。
综上讨论,当研究目的包括“研究前沿”和“知识基础”时,选择共引分析较为合理;而当研究目的为“研究热点”时,共词分析更加合适;为了进一步识别和解读“研究趋势”、“主题突变”或“知识结构”等,则可以综合分析多种类型的科学知识图谱。
二、充分掌握研究目标结构体系,制定科学合理的文献检索策略
对于科技文本数据而言,索引型数据库通常收录了除了正文以外的所有文献信息,而且还增加了数据库本身对论文的标引(例如论文的科学领域、被引次数以及使用情况等)。相比而言,Web of Science(WoS)和Scopus的数据结构是最为完整的,Derwent和CSSCI次之,CNKI的完整性最小。CiteSpace分析的数据是以WoS数据为标准的,即其他数据库收集的数据都要先经过转换,成为WoS的数据格式。通常,文献题录数据都会包含PT(文献类型),AU(作者),SO(期刊),DE(关键词),AB(摘要),C1(机构)以及CR(参考文献)。下表列出了CiteSpace可以处理的常用数据源及对应功能:
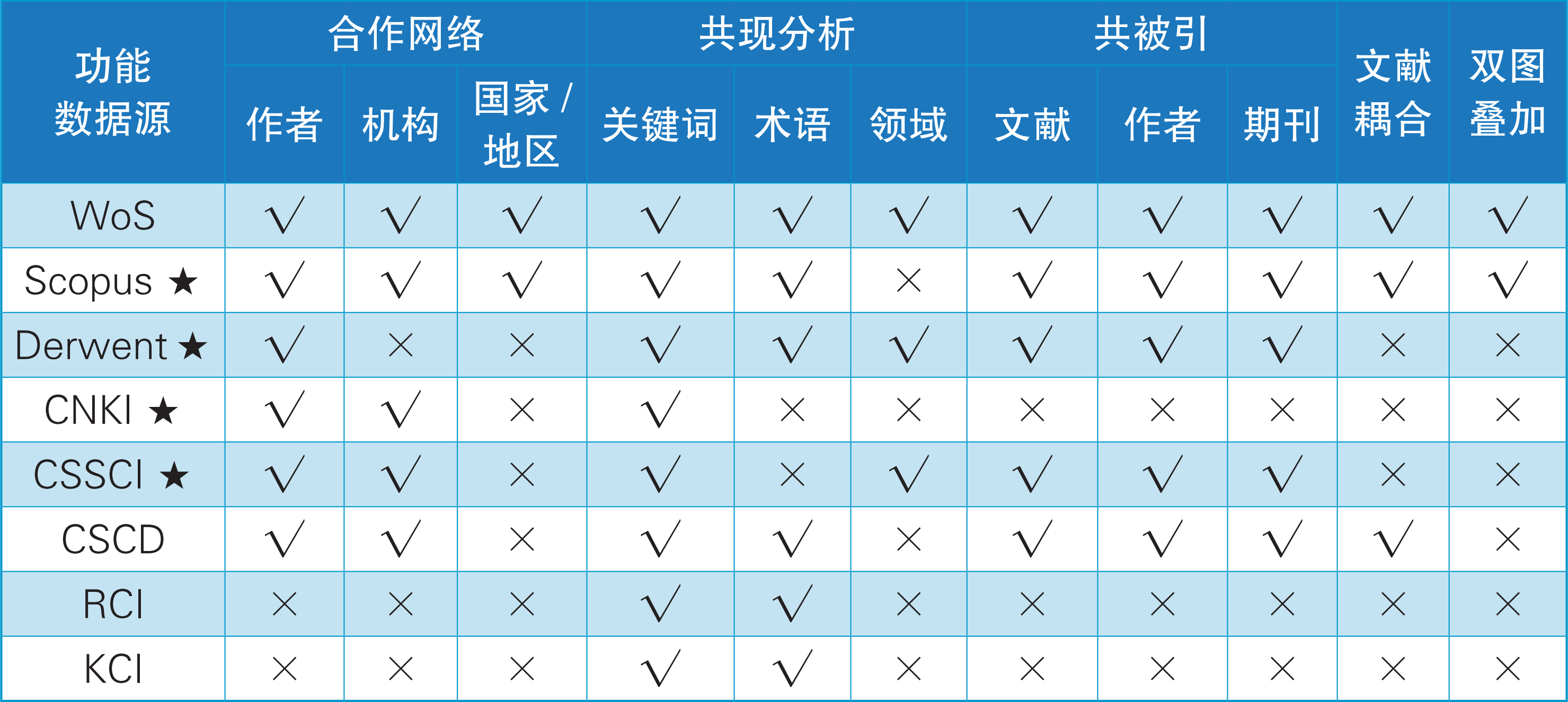
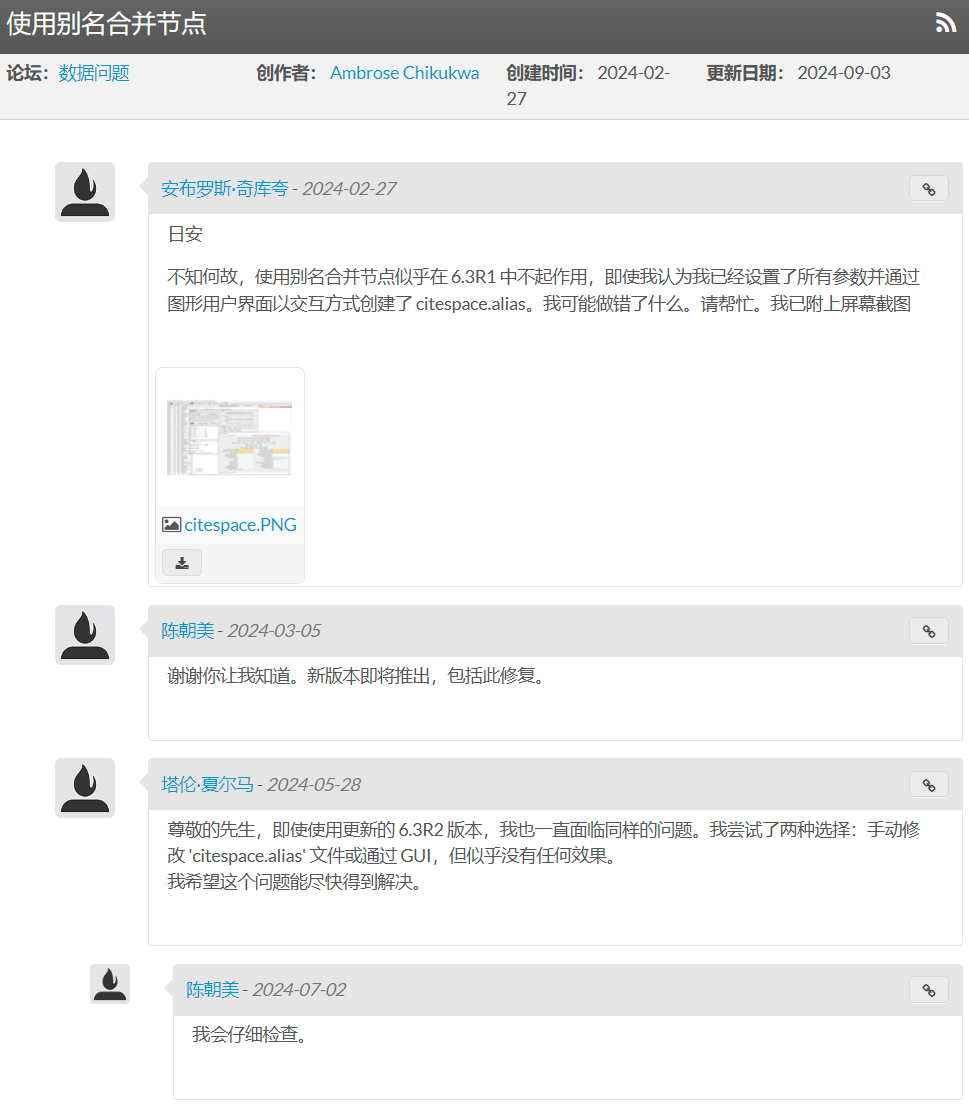
表中“×”为不能分析的功能,或不推荐分析的功能;“★”的数据需要经过CiteSpace的转换。需要特别注意的是,CNKI数据不支持绝大多数CiteSpace中的分析功能,且在进行关键词共现分析时也不能从标题或摘要提取聚类命名(因为内置的算法只能用于提取英文术语,在一些版本的CiteSpace中,将中文数据中论文的英文标题放在了TI字段,此时使用标题来进行聚类命名也是可以的,但是所得到的聚类标签都为英文)。此外,CiteSpace官网提供的最新免费版本6.3.R1(截止本文撰写日期2025-01-03)存在功能性BUG,导致别名合并节点功能无法使用,该功能对共现分析和合作网络尤为重要。因此,个人不建议使用CNKI数据,尤其是在6.3.R1版本CiteSpace的情况下。有关该BUG的讨论和陈超美教授本人的回复如下图所示(内容已翻译)。
Web of Science数据库是商业性的索引数据库,因此用户需要机构在订阅的前提下才有权限访问。在实际使用时,一些高校的数据回溯时间并不完整,据调研,目前国内只有少数机构购买了比较全的WoS核心数据库,因此在进行数据检索时要注意当前数据库的订阅情况。下面对获取Web of Science核心数据集的步骤进行具体介绍:
第1步,登录Web of Science数据库首页,默认情况下检索的数据会是“所有数据库”,用户需要切换到“Web of Science核心合集”,以保证所采集的数据可以用于进一步的科学计量与知识图谱分析。
第2步,制定数据检索策略,在此之前,首先应当充分理解和明确所研究目标领域的结构体系,进而根据实际需要,可以考虑系统性的分层次构建综合检索模型,最终制定合适的检索策略。在使用CiteSpace等可视化工具时,前期检索结果的质与量会直接影响到后续分析的深度和可信度,只有在检索阶段完成了严谨细致的布局,才能在后续的信息可视化、知识图谱绘制以及科学计量分析中获得更具说服力与解释力的成果。以陈超美教授在2017年发表的关于Science Mapping的综述论文中构建的文献综合检索模型为例,如下图所示:
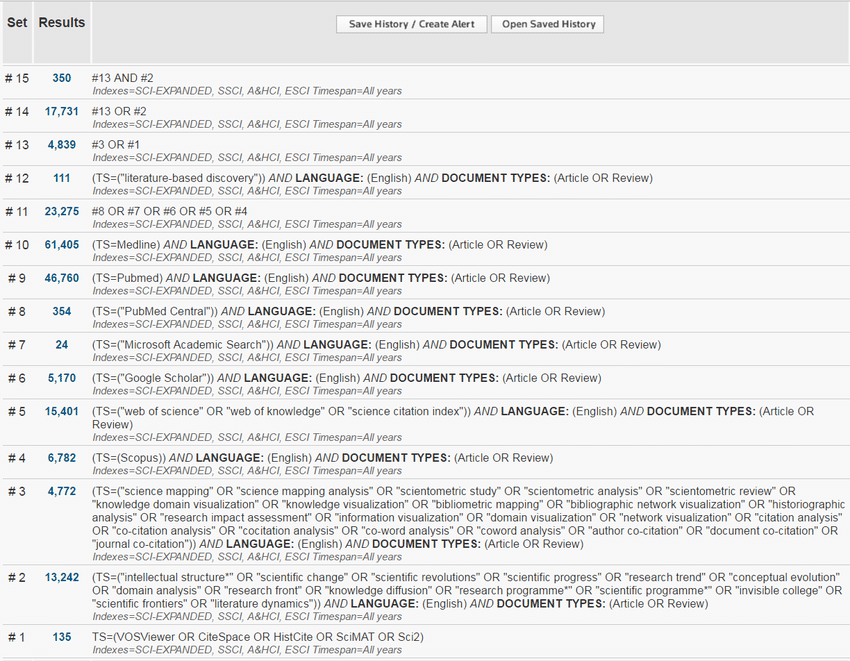
这个检索模型中包含了Science Mapping有关的工具(#1)、理论(#2)、方法(#3)、数据库(#4~#11)等,而最终使用的检索表达式则是在后续的组合尝试、综合取舍后选取了#1、#2和#3的并集,共计有17731篇。
在这个例子中,检索模型的各个子集共同构成了目标研究领域的结构体系。事实上,我们对模型的构筑过程同时也是对目标领域整体框架的系统化认识过程,这种认识并不仅限于罗列概念或关键词,而是基于对该领域内不同层面要素的梳理与划分。例如,可以在分别确定理论基础、主要研究方法、常用分析工具等要素之后,再思考它们之间的关联与交叉。正是这样的“拆解-重组”过程,使得检索表达式能够更具层次性与针对性。
在最终确定数据检索策略前,我们往往还需要面临“查全率”和“查准率”的取舍问题,其权衡会直接影响检索结果的规模与质量,并最终决定研究数据的可用性和分析的深度。在实际操作中,如果检索式设置得过于宽泛,就能在更大程度上提高查全率,但也意味着可能会纳入数量可观的无关文献,产生取伪错误;反之,若一味强调查准率而使检索式过于明确和严格,则虽然能够获取更集中、更有针对性的文献集合,却很可能遗漏关键研究或潜在的新兴方向,造成拒真错误。
对于平时研究时最常采取的关键词或主题检索,就是一个查准率较高而查全率较低的检索方案,在科学计量分析中通常都需要对检索结果进行扩展,提高检索结果的查全率。超美教授对此的观点是:“从实用的角度讲,相对于对原始的检索结果不停的进行精炼和清洗直到将所有无关的研究主题都排除在外,一个更容易也是更有效的办法是(留着它们,但是在生成的科学知识图谱中),解读的时候跳过这些个研究聚类或分支就是了。”除上述举例中提到的“综合检索模型”外,还可以通过“施引文献扩展”等方式,此处不再详细介绍。
第3步,检索结果及导出,用户需要点击检索结果页面的“导出”功能,并选择“纯文本文件”,以将所检索的数据下载为可分析的数据格式。在数据导出的界面中,输入要导出的数据序号区间,记录内容所在的位置选择“全记录与引用的参考文献”(每次最多支持导出500条数据,若没有该选项可能是由于第1步中没有切换到“Web of Science核心合集”)。需要注意的是,CiteSpace对分析的数据文本命名有特殊要求,文件名必须要命名为“download_xxx”的格式。此外,可以点击结果页面右上侧的“分析检索结果”功能,借助平台自带的分析功能,得到论文年度分布、作者、机构、国家/地区,基金以及论文的科学分类等信息,通过该界面的“下载”功能,可以将描述性统计结果导出为TXT文档,方便导入Excel中进行统计与绘图分析。
三、基于CiteSpace的知识图谱构建与解读技巧
CiteSpace的功能界面主要分为两大模块:一是软件最初进入时用于设置各类分析参数、数据导入及运行控制的区域;二是对分析结果进行可视化展示和后续加工的界面。只有先对这些区域的一些重要功能认识正确,才能保证后续知识图谱构建的有效性。针对界面中各项功能的详细介绍,官方的中文使用指南讲解非常详尽,但里面也存在一些容易混淆或被忽视的细节,需要我们在实践中多加关注。
3.1 图谱节点与连线:如何正确解读?
首先,对于CiteSpace生成的各种图谱中节点和连线的含义,在论文主题、关键词以及科学领域的共现图谱中,节点的大小代表它们出现的频次,它们之间的连线表示共现关系和强度;而在共被引图谱中,节点的大小反映了文献、作者或者期刊的被引次数。网络连线的颜色反映了首次共被引(或首次共现)的时间。
需要注意的是,节点的大小虽能直观展现其出现或被引的频次,但并不必然意味着该节点在领域中具有更高的分析价值或更深层的学术意义。举例来说,在以关键词或主题检索为数据来源得到的共现图谱中,那些出现在检索式中的关键词节点或一些较为宽泛的名词术语节点往往较大,然而它们通常难以提供实质的洞见。正因如此,我们在使用CiteSpace进行图谱分析时,需要结合研究背景和专业判断,以及对应的统计指标,仔细甄别其中所承载的信息,避免想当然的判断其价值或“好坏”。
3.2 网络裁剪:何时使用、如何使用?
在图谱构建过程中,当网络比较密集时,可以通过Pruning区域的裁剪功能保留重要的连线来提高网络可读性,但建议在初步分析阶段不要对网络进行裁剪。该模块主要有两种网络剪裁方法,分别为Minimum Spanninng Tree(MST,最小树法)和Pathfinder Network(PFNET,寻径网络)。其中,Pathfinder的作用是简化网络并突出其重要的结构特征,优点是具有完备性(唯一解),而MST则不具备这一特性。MST的优点是运算简捷,能很快得到结果。需要注意的是,两种网络剪裁方法作用的对象是网络中的连线,因此网络节点数量不会发生变化。
按CiteSpace的设计,所处理的是一组网络序列(比如每年一个网络),最后产生合并后的网络,这样既可以选择简化序列中的每个网络,也可以选择简化最终合成的综合网络,二者之间是相互独立,且不相矛盾的,两种功能可以同时使用,但建议首先尝试Pruning the Merged Network(对合并后的网络进行裁剪)方法,若直接使用Pruning Sliced Networks(对每个切片的网络进行裁剪)可能会导致网络过于分散。
3.3 聚类评价分析:Cluster Explorer的巧妙用法
在聚类完成后,会在可视化结果的左上角显示Modularity(模块化值)和Silhouette(剪影值),它们都是用来衡量聚类效果的参数,具体的原理如下:
Modularity是网络模块化的评价指标,一个网络的Modularity值越大,则表示网络得到聚类越好。Q的取值区间为[0,1],Q>0.3时就意味着得到的网络社团结构是显著的。
Silhouette值是用于评价聚类效果的参数。通过衡量网络同质性的指标来对聚类进行评价,Silhouette值越接近1,反映网络的同质性越高,Silhouette为0.7时聚类结果是具有高信度的。在0.5以上,可以认为聚类结果是合理的。注意:在聚类内部成员很少时,这个值的信度会降低。
CiteSpace提供了三种文本处理方法,用以从施引论文的标题、关键词、摘要、领域或被引文献中来提取聚类标签,这个命名可以认为是领域的研究前沿,同时,聚类标签的命名算法提取的研究术语强调了每个集群的独特方面(unique aspect of a cluster)。但在实际研究中,仍须配合人工判断与修正,确保对聚类主题的描述更准确、贴合研究现实。
此外,CiteSpace根据概念模型设计了聚类信息展示界面(Cluster Explorer),如下图所示,界面中提供了聚类信息查询(Clusters)、施引文献信息(Citing Articles)、被引文献信息(Cited Reference)以及从施引文献中提取的总结聚类的句子(Summary Sentences)查询四个窗口。该界面能够清晰地了解到与聚类相关的多个方面的信息,是文献共被引分析中最常用的一个功能。

图中左侧中间窗口显示的是施引文献,这些文献代表了研究前沿。Coverage表示该论文引用对应聚类中的被引文献数量;GCS表示对应文献在Web of Science中的被引次数;LSC表示该论文在所下载数据集中的被引次数。对应的,右侧中间窗口显示的是被引文献,这些文献反映的是知识基础,也是直接在图谱中显示的节点信息。最后,底部的窗口显示了从施引文献的摘要中,按照Centrality或PageRank算法提取的句子,有利于理解各类中论文的研究内容。
3.4 快速生成总结分析报告
CiteSpace提供的Generate a Narrative功能,可以一键导出对当前网络或聚类中最关键结果的分析报告,包含了MAJOR CLUSTERS(主要聚类及其聚类标签)、CITATION COUNTS(高被引文献)、BURSTS(爆发性文献)、CENTRALITY(高中心性文献)以及SIGMA值,如下图所示:
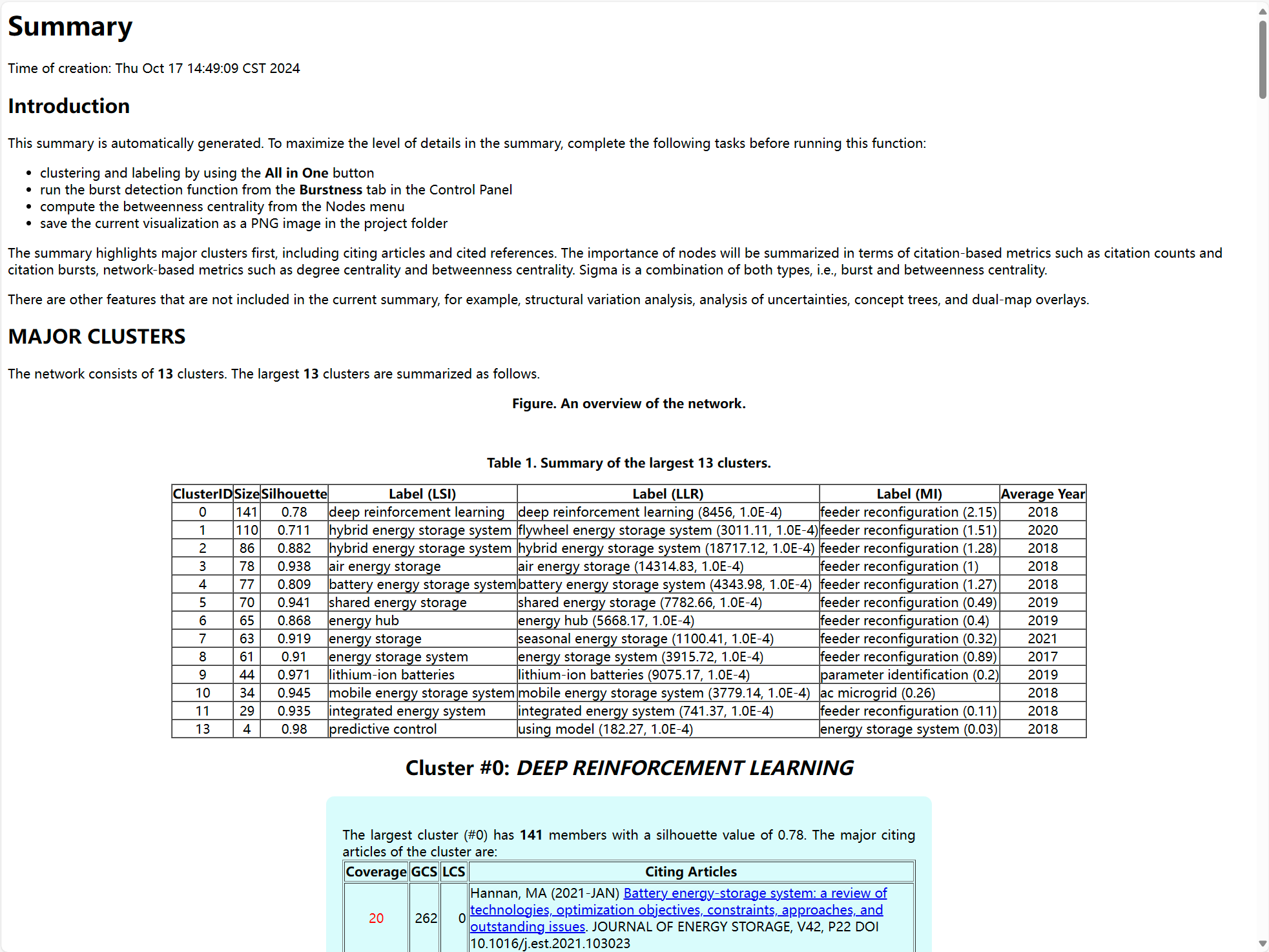
这些信息可以帮助我们在短时间内掌握哪些文献在网络里最“显眼”、或在哪些聚类里可能蕴藏着研究热点或潜在新方向。
暂无评论